[In preview] Public Preview: Azure Migrate expands support for migrations with Ultra SSD
May 28, 2025
Using bicep-deploy in GitHub action, part 1 Bicep deployment
May 28, 2025
Hello folks!
The rate of change in tech is the most crazy I’ve experienced in my career. What you knew yesterday is quickly replaced with major changes a week or two later. The generative AI space is one of those areas that seems to change on a daily basis, and with these changes comes updated and new patterns and products. Given some major changes over the past few months, I’ve decided to kick off a new blog series that will cover generative AI in Azure for the generalist. The focus will be on folks like myself that sit squarely in the generalist vertical. In this series I’ll cover new topics as well as revisiting topics I’ve covered in the past and how they have changed.
In spirit of that latter point, tonight I’ll be covering an AWESOME new feature in Azure API Management (APIM).
The Background
I’ve talked pretty extensively about APIM’s role in the generative AI space where it provides the features and functionality of the architectural component of a Generative AI Gateway (GenAI Gateway). So what is a GenAI Gateway? Well, you see, someone at Forrester/Gartner needed to create a new phrase that vendors could adopt and sell existing products under, they had a pitch meeting, and yadda yadda yadda. But seriously, in its most simple sense a GenAI Gateway is essentially an API Gateway with additional functionality and features specific to the challenges of doing Generative AI at scale. These challenges can include fine-grained authorization, rate limiting, usage tracking, load balancing, caching, additional logging and monitoring and more.
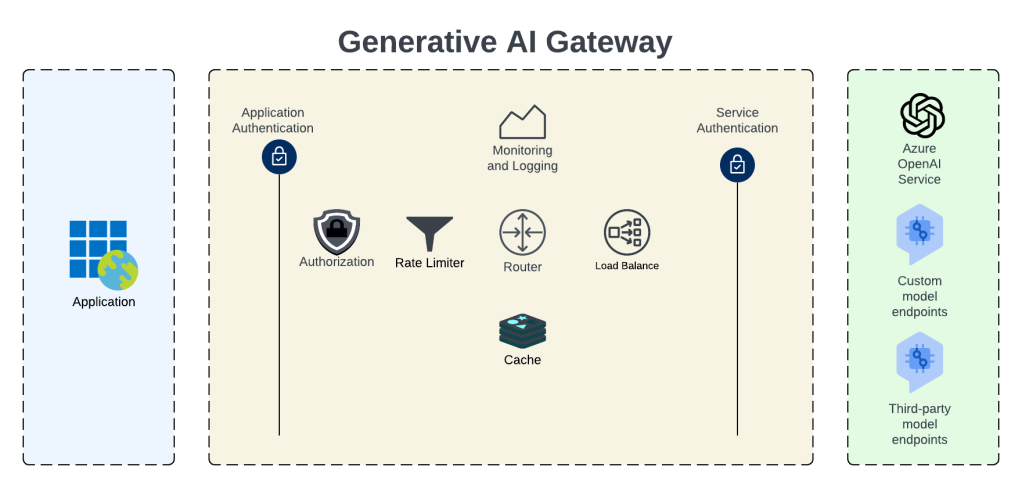
Cloud providers jumped at the chance to add this functionality to their existing native API Gateway products. Microsoft began integrating this functionality into APIM first with load balancing, then with throttling based upon token usage and token tracking for charge backs and sharing model quota across an enterprise, and semantic caching for cost reduction and improved response times. One of the areas that was somewhat of a gap was prompt and response logging.
Back in 2023 I wrote an article about the challenges of prompt and response logging when using a generative AI gateway pattern, and specifically some of the challenges around when APIM was used as the gateway. The history of how folks tried to tackle the issue is pretty interesting context to understand how we ended up where we were.
Before I jump into that history, it’s worth understanding why you should care about prompt and response logging. Those cares are typically grouped in two buckets:
- Operational
- Security
In the operational bucket we care about these things because they provide great insight into how our users are using these tools to identify commonly asked questions. For example, if we see a question pop up a lot, maybe it’s something we need to add to a user-facing FAQ. Or perhaps we build a workflow into our app that checks commonly asked questions and provides an answer before we call an LLM in order to save some costs and time. There are many creative uses to having these things saved and available.
In the security bucket we care because we want to ensure the LLMs are used responsibly. We don’t want people abusing the LLMs and getting instructions on how to malicious things and we also want to monitor them to ensure we don’t see odd behavior that might be indicative of an attacker who may have compromised a chat bot. Lastly, we capture this because it’s only a matter of a time before some government somewhere in the world pushes legislation that requires us to. It’s coming folks.
Now let’s talk the history of how folks tried to solve this problem.
First, we tried logging requests and responses to Application Insights using the built-in integration with APIM. This worked great until the max tokens for prompts grew too large such that requests and responses started getting truncated. Next, we tried using APIM’s integration with Event Hub (logger) in combination with complex custom APIM policy to parse the request and response, extract the prompt and completion, and deliver to an Event Hub for it to get picked up by some type of automated function and stored in some type of backend data store like a CosmosDB. This worked for a short time where folks were largely experimenting with how the LLMs (large language models) worked with their data but started to fall apart when these LLMs were baked into a chat bot handed out to users (they were also a nightmare to maintain due to frequent API changes to the structure of requests and responses). The reason for this is chat bots demand streaming based completions which deliver the tokens as they generated (which seems more human like) vs the user waiting for the entire completion to be generated. APIM would end up buffering the response and breaking the user experience. To solve this problem, folks were introducing custom code to do the parsing outside of APIM (such as this creative solution by my peer Shaun Callighan). Writing custom code, running it somewhere, and integrating it into APIM was a tough pill to swallow. Most of my customer base either accepted prompt and response logging would be dependent on the developer baking it into their application or they would simply accept not getting that information for the time being.
What’s New
Kind of a shitty situation to be in, right? Well, I have good news for you. Last week the APIM Product Group (PG) released a stellar new feature to support prompt and response logging (both streaming and non-streaming) with a few clicks of the mouse (or slight modifications of code). This morning I had a chance to muck around with it and I wanted to get out this quick article to share with folks the basics of setting this up and provide a bit of detail into how it works (I’ll be updating post this as I experiment more).
The feature is now available directly as an additional log emitted by the APIM instance via the diagnostic settings. This means you can stream these logs to a Log Analytics Workspace, Azure Storage Account, or on to an Event Hub where you send it to any place your heart desires.
Setup
Setting this feature up is pretty cake and requires only a few steps to get it done.
First up you’ll need to enable the additional log in diagnostic settings as seen below.

Once the new diagnostic setting is enabled, you then need to enable it for your API that represents your instance of the an Azure OpenAI resource(s) or Azure AI Foundry (FKA Azure AI Service) instance hosting your LLMs.

Once the feature is enabled in both places, the events should begin to get captured in around 15 or so minutes. I chose to send mine to a Log Analytics Workspace and had a new table named ApiManagementGatewayLlmLogs appear (took about 15 minutes to finally appear) which contains events related to my operations against the LLMs. Each log entry represents a 32KB chunk of the request and response for up to 2MB. The SequenceNumber field is used to denote the order of the chunks as seen in the image below with the CorrelationId field requesting the unique identifier for each request and response.

Expanding an event gives you the ability to review the prompt and response in full detail. This particular request spanned three separate events (sequence 0-2) with the first sequence (0) containing the prompt, completion, and total tokens and the second sequence (1) including the prompt and last sequence (2) containing the model’s response.

I tested with both a multi-modal model (gpt-4o) and a reasoning model (o1) and both sets of events were captured. I haven’t seen an authoritative list for which models are supported, but when I do I’ll update this post with a link.
I’m also waiting to hear back from the PG as to how APIM determines it’s a call to an LLM. My guess is by operation name, but waiting on that response as well. I haven’t tested other operations such as creating embeddings yet, so if you do, feel free to reply to this post with your findings. If I’m able to get a full list of operations supported by this logging, I’ll update the post.
Wrapping It Up
That about sums up this quick post. My main goal here was to publicize this new feature because it’s a real game changer for APIM and addresses a major pain point of Generative AI Gateways in general. It’s been really cool to see this from the beginning, and I’m not sure about other folks, but I love understanding the journey a technology takes, the new problems that pop up, and the solutions that solve those problems. It really helps give context to why the solution looks the way it does.
See you next post!


{kind=link}
{kind=link}